一. 创建表并insert 数据
create table ta (id number,name varchar2(10));
create table tb(id number,job varchar2(10));
begin
for i in 1..1000000 loop
begin
insert into ta values(i,'dave');
commit;
end;
end loop;
end;
begin
for i in 1..1000000 loop
begin
if i<10 then
insert into tb values(i,'boy');
elsif i<20 and i>10 then
insert into tb values(i,'girl');
commit;
end if;
end;
end loop;
end;
二.在没有索引的情况关联ta 和 tb 查询
相关链接:
Oracle Optimizer CBO RBO
http://blog.csdn.net/tianlesoftware/archive/2010/08/19/5824886.aspx
多表连接的三种方式详解 HASH JOIN MERGE JOIN NESTED LOOP
http://blog.csdn.net/tianlesoftware/archive/2010/08/21/5826546.aspx
Oracle Hint
http://blog.csdn.net/tianlesoftware/archive/2010/08/23/5833020.aspx
2.1 optimizer选择 CBO(10g 默认)
--ta 在前
select ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;

--tb 在前
select ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;
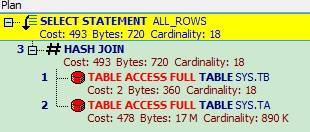
总结:
两条SQL 执行计划是一样的, ta和tb 的顺序没有影响。
因为ta和tb 的记录相差较大,ta是100万,tb 只有20条。 所以这里CBO 选择使用Hash Join。
CBO 选择2个表中记录较小的表tb,将其数据放入内存,对Join key构造hash 表,然后去扫描大表ta。 找出与散列表匹配的行。
2.2 对ta和tb 的ID 建b-tree 索引后在查看
--建索引
create index idx_ta_id on ta(id);
create index idx_tb_id on tb(id);
--tb 在前
select ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;

--ta 在前
select ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;
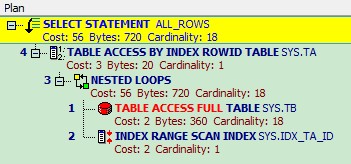
总结:
执行计划还是一样,不同的是表之间的关联模式发生的改变,从Hash Join 变成了Nested Loops。
Nested loop一般用在连接的表中有索引,并且索引选择性较好的时候. 在我们这个示例中,CBO 选择把返回结果集较小的表tb 作为outer table,CBO 下,默认把outer table 作为驱动表,然后用outer table 的每一行与inner table(我们这里是ta)进行Join,去匹配结果集。 由此可见,在tb(inner table) 有索引的情况,这种匹配就非常快。
这种情况下整个SQL的cost:
cost = outer access cost + (inner access cost * outer cardinality)
从某种角度上看,可以把Nested loop 看成2层for 循环。
2.3 使用RBO 查看
在10g里,optimizer 默认已经使用CBO了,如果我们想使用RBO, 只能通过Hint 来实现。
-- ta 在前
select /*+rule*/ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;
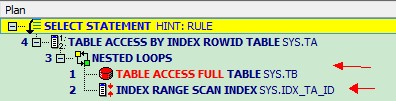
SYS@anqing2(rac2)> select /*+rule*/ta.id, ta.name,tb.job from ta,tb where ta.id<100 and ta.id=tb.id;
Elapsed: 00:00:00.00
-- 注意这个SQL里,我们加了ta.id<100 的条件
Execution Plan
----------------------------------------------------------
Plan hash value: 3943212106
---------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | TABLE ACCESS BY INDEX ROWID | TB |
| 2 | NESTED LOOPS | |
| 3 | TABLE ACCESS BY INDEX ROWID| TA |
|* 4 | INDEX RANGE SCAN | IDX_TA_ID |
|* 5 | INDEX RANGE SCAN | IDX_TB_ID |
---------------------------------------------------
-- 当我们加上条件之后,就先走ta了,而不是tb。 因为先走ta,用ta的限制条件过滤掉一部分结果,这样剩下的匹配工作就会减少。
Predicate Information (identified by operation id):
---------------------------------------------------
4 - access("TA"."ID"<100)
5 - access("TA"."ID"="TB"."ID")
Note
-----
- rule based optimizer used (consider using cbo)
--tb 在前
select /*+rule*/ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;

总结:
这2个就区别很明显。 因为Oracle对sql的解析是从后向前的。 那么当先遇到tb时,那么会对tb进行全表扫描,然后用这个结果匹配ta。因为ta有索引,所以通过索引去匹配。
如果先遇到ta,那么就会对ta进行全表扫描。 因为2个表的差距很大,所以全表扫描的成本也就很大。
所以在RBO 下,大表在前,小表在后。这样就会先遇到小表,后遇到大表。 如果有指定限定的where 条件,会先走限定条件的表。
2.4 drop 索引之后,在走RBO
drop index idx_ta_id;
drop index idx_tb_id;
--ta 在前
select /*+rule*/ta.id, ta.name,tb.job from ta,tb where ta.id=tb.id;

--tb 在前
select /*+rule*/ta.id, ta.name,tb.job from tb,ta where ta.id=tb.id;

总结:
这里选择了Sort Merge Join 来连接2张表。Sort Merge join 用在没有索引,并且数据已经排序的情况.
我们表中的记录是按照顺序插叙的,所以符合这个条件。 SQL 的解析还是按照从后往前,所以这里ta和tb 在前先扫描的顺序不一样,不过都是全表扫描。 效率都不高。
2.5 引深一个问题:使用 字段名 代替 *
* 能方便很多,但在ORACLE解析的过程中, 会通过查询数据字典,会将’*’ 依次转换成所有的列名,这就需要耗费更多的时间. 从而降低了效率。
SYS@anqing2(rac2)> set timing on
SYS@anqing2(rac2)> select * from ta where rownum=1;
ID NAME
---------- ----------
1 dave
Elapsed: 00:00:00.03
SYS@anqing2(rac2)> desc ta
Name Null? Type
----------------------------------------- -------- ----------------------------
ID NUMBER
NAME VARCHAR2(10)
SYS@anqing2(rac2)> select id,name from ta where rownum=1;
ID NAME
---------- ----------
1 dave
Elapsed: 00:00:00.02
时间已经缩短。 但不明显,用Toad 来查看一下:

写全字段,执行时间是161 毫秒,用* 是561毫秒。 差距很明显。
查看一下他们的执行计划:
SYS@anqing2(rac2)> select * from ta where rownum=1;
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 761731071
---------------------------------------------------------------------------
| id | operation | name | rows | bytes | cost (%cpu)| time |
---------------------------------------------------------------------------
| 0 | select statement | | 1 | 20 | 7 (72)| 00:00:01 |
|* 1 | count stopkey | | | | | |
| 2 | table access full| ta | 890k| 16m| 7 (72)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(ROWNUM=1)
Note
-----
- dynamic sampling used for this statement
SYS@anqing2(rac2)> select id,name from ta where rownum=1;
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 761731071
---------------------------------------------------------------------------
| id | operation | name | rows | bytes | cost (%cpu)| time |
---------------------------------------------------------------------------
| 0 | select statement | | 1 | 20 | 7 (72)| 00:00:01 |
|* 1 | count stopkey | | | | | |
| 2 | table access full| ta | 890k| 16m| 7 (72)| 00:00:01 |
---------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter(ROWNUM=1)
Note
-----
- dynamic sampling used for this statement
注意:
使用 * 和 写全字段名,他们的执行计划是一样的,但是执行时间不一样。
-------------------------------------------------------------------------------------------------------
Blog: http://blog.csdn.net/tianlesoftware
Email: dvd.dba@gmail.com
DBA1 群:62697716(满); DBA2 群:62697977(满) DBA3 群:62697850(满)
DBA 超级群:63306533(满); DBA4 群: 83829929 DBA5群: 142216823
DBA6 群:158654907 聊天 群:40132017 聊天2群:69087192
--加群需要在备注说明Oracle表空间和数据文件的关系,否则拒绝申请
分享到:




相关推荐
§1.1.2 表空间与数据文件 24 §1.1.3 Oracle实例(Instance) 24 §1.2 Oracle文件 26 §1.2.1 数据文件 26 §1.2.2 控制文件 26 §1.2.3 重做日志文件 26 §1.2.4 其它支持文件 26 §1.3 数据块、区间和段 28 §...
其三、职业方向多:Oracle数据库管理方向、Oracle开发及系统架构方向、Oracle数据建模数据仓库等方向。 四、 如何学习 认真听课、多思考问题、多动手操作、有问题一定要问、多参与讨论、多帮组同学 五、 体系结构 ...
1.6.2 多表插入 15 1.7 UPDATE语句 17 1.8 DELETE语句 20 1.9 MERGE语句 22 1.10 小结 24 第2章 SQL执行 25 2.1 Oracle架构基础 25 2.2 SGA-共享池 27 2.3 库高速缓存 28 2.4 完全相同的语句 29 2.5 SGA-...
1. 前言 5 1.1 目的 5 1.2 文档说明 5 1.3 词汇表 5 1.4 参考资料 5 2. PLSQL程序优化原则 6 2.1 导致性能问题的内在原因 6 2.2 PLSQL优化的核心思想 6 2.3 ORACLE优化器 6 ...4. 性能测试工具设计思想 31
通过学习《Oracle Database 11g完全参考手册》,您可以了解如何实现最新的安全措施,如何调优数据库的性能,如何部署网格计算技术。附录部分内容丰富、便予参照,包括Oracle命令、关键字、功能以及函数等。 目录 ...
通过学习《Oracle Database 11g完全参考手册》,您可以了解如何实现最新的安全措施,如何调优数据库的性能,如何部署网格计算技术。附录部分内容丰富、便予参照,包括Oracle命令、关键字、功能以及函数等。 目录 ...
1.9.3 多对多关系 26 1.10 创建数据库 27 1.10.1 修改创建模板的脚本文件 27 1.10.2 创建数据库后修改 MAXDATAFILES 27 1.10.3 使用OEM 28 第2章 硬件配置研究 30 2.1 结构概述 30 2.2 独立主机 31 2.2.1 磁盘阵列...
充分利用现有的 IT 投资 与异构系统的“可热插拔”集成 Oracle商务智能 –普及商务智能应用 Oracle BI 应用产品 基于 OBIEE 构建的预建分析应用程序 Oracle BI Standard Edition One Main BI Product for SMB: OBI ...
CruiseYoung提供的带有详细书签的电子书籍目录 ... OCPOCA认证考试指南全册:Oracle Database 11g(1Z0-051,1Z0-... 12.1 使用同等联接和非同等联接编写SELECT语句访问多个表的数据 398 12.1.1 联接的类型 398 12.1.2 ...
第1章 Oracle服务器技术与关系范例 1.1 定位服务器技术 1.1.1 Oracle服务器的体系结构 1.1.2 OracleApplicationServer 1.1.3 OracleEnterpriseManager 1.1.4 网格计算 1.1.5 开发工具和语言 1.2 理解...
在FROM后面的表中的列表顺序会对SQL执行性能影响,在没有索引及ORACLE没有对表进行统计分析的情况下ORACLE会按表出现的顺序进行链接,由此因为表的顺序不对会产生十分耗服务器资源的数据交叉。(注:如果对表进行...
Oracle9i初始化参数中文说明 Blank_trimming: 说明: 如果值为TRUE, 即使源长度比目标长度 (SQL92 兼容) 更长, 也允许分配数据。 值范围: TRUE | FALSE 默认值: FALSE serializable: 说明: 确定查询是否获取表级...
很多情况下ORACLE并不能为我们的SQL语句选择最有效的驱动表, 在我们自己确定了合适的驱动表之后,可以使用HINT: ORDERED,LEADING来指定合适的驱动表 WHERE子句中的连接条件书写顺序 那些可以过滤掉最大数量记录的...
CruiseYoung提供的带有详细书签的电子书籍目录 ... 对应的书籍资料见: OCPOCA认证考试指南全册:Oracle Database 11g(1Z0-051... 12.1 使用同等联接和非同等联接编写SELECT语句访问多个表的数据 398 12.1.1 联接的类型...
关系模型的参照完整性可以通过在create table中用foreign key (<外键>) references <被参照表名> (<与外键对应的主键名>)进行约束定义。 1.4.3 用户定义完整心 在create table语句中可以根据应用要求,定义属性以及...
# MySQL的最大连接数,如果服务器的并发连接请求量比较大,建议调高此值,以增加并行连接数量,当然这建立在机器能支撑的情况下,因为如果连接数越多,介于MySQL会为每个连接提供连接缓冲区,就会开销越多的内存,...
多表查询时,可给表起别名。(给列起别名,列<空格>列别名;给表起别名,表<空格>表别名;)。 如:Select first_name EMPLOYEES, 12*(salary+100) AS MONEY, manager_id "ID1" From s_emp E; 4、字段的拼接,可用双...