翻译自:http://www.mssqltips.com/sqlservertip/2718/sql-server-index-column-order--does-it-matter/?utm_source=dailynewsletter&utm_medium=email&utm_content=headline&utm_campaign=2012619
问题:
当设置表的索引时,在性能上有一个微妙的平衡:太多的索引将影响你的INSERT/UPDATE/DELETE操作。但是索引不足又将影响你的SELECT操作。本文将着眼于索引的列顺序和如何影响查询计划及性能。
解决方案:
示例SQLServer表和数据集:
-- Tablecreation logic
CREATE TABLE[dbo].[TABLE1]
([col1][int]
NOT NULL,[col2]
[int]NULL,[col3]
[int] NULL,[col4][varchar](50)NULL)
GO
CREATE TABLE[dbo].[TABLE2]
([col1][int]
NOT NULL,[col2]
[int]NULL,[col3]
[int] NULL,[col4][varchar](50)NULL)
GO
ALTER TABLEdbo.TABLE1ADD
CONSTRAINT PK_TABLE1
PRIMARY KEY
CLUSTERED (col1)
GO
ALTER TABLEdbo.TABLE2ADD
CONSTRAINT PK_TABLE2
PRIMARY KEY
CLUSTERED (col1)
GO
--Populate tables
DECLARE
@val INT
SELECT @val=1
WHILE @val< 1000
BEGIN
INSERT
INTO dbo.Table1(col1,col2,
col3,
col4)VALUES(@val,@val,@val,'TEST')
INSERT
INTO dbo.Table2(col1,col2,
col3,
col4)VALUES(@val,@val,@val,'TEST')
SELECT
@val=@val+1
END
GO
--Create multi-column index on table1
CREATE NONCLUSTEREDINDEX
IX_TABLE1_col2col3ONdbo.TABLE1(col2,col3)
WITH (STATISTICS_NORECOMPUTE=OFF,
IGNORE_DUP_KEY =
OFF,
ALLOW_ROW_LOCKS=ON,
ALLOW_PAGE_LOCKS =
ON)
ON [PRIMARY]
GO
在运行下面的代码前请先打开执行计划(Ctrl+M)和打开统计IO的语句:SET STATISTICS IO ON
单表查询例子:
在第一个例子里面,我们将使用在where子句中的一列来查询。第一个查询中where子句的索引使用第二列(col3),第二个查询使用第一列(col2)。注意这里使用了“DBCC DROPCLEANBUFFERS”,用于确保没有缓存带来的影响,代码如下:
DBCC DROPCLEANBUFFERS
GO
SELECT * FROM dbo.TABLE1 WHEREcol3=88
GO
DBCC DROPCLEANBUFFERS
GO
SELECT * FROM dbo.TABLE1 WHEREcol2=88
GO
执行后查看执行计划如下:


可以看到,第一个查询使用第二列(col3)的索引是在表上执行索引扫描,且没有用到刚才建立的索引。第二个查询使用了表查找,使得在表里只需要使用更少的资源。第一个查询读了6次,而第二个查询只读了4次。
执行查询后,你应该大概猜到,当表越来越大的时候,性能优势就显现出来了。
两表关联查询例子:
在下一个例子中,查询使用同样的where子句,但增加了一个inner join 关联另外一个表。第一个查询的where子句使用col3,并使用col2来关联表。
第二个查询的where子句使用col2,并使用col3来关联表。
同样,先执行DBCC DROPCLEANBUFFERS来确保缓存已经清空。代码如下:
DBCC DROPCLEANBUFFERS
GO
SELECT *
FROM dbo.TABLE1 INNER JOIN
dbo.TABLE2 ON dbo.TABLE1.col2 = dbo.TABLE2.col1
WHERE dbo.TABLE1.col3=255
GO
DBCC DROPCLEANBUFFERS
GO
SELECT *
FROM dbo.TABLE1 INNER JOIN
dbo.TABLE2 ON dbo.TABLE1.col3 = dbo.TABLE2.col1
WHERE dbo.TABLE1.col2=255
GO
执行计划如下:

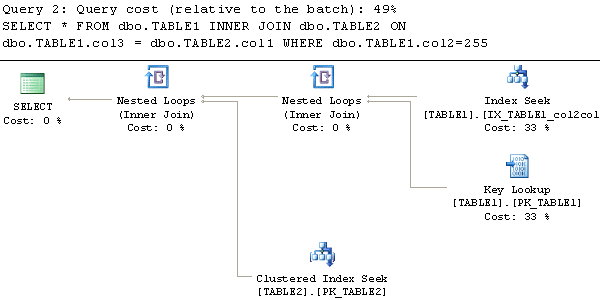
从执行计划可以看到,当用于关联表的列也在索引中,但不是第一列时,会执行索引扫描。第二个查询中索引的第一列来关列,会使用索引查找。从IO来看,同样索引查找的读次数会更小。
总结:
从这些例子中,可以看到索引列的顺序对表的查询也有影响。当创建索引时,先确认你总是对尽可能小的集合进行操作,这意味着索引能从where子句中的列开始。另外,对order by子句中的列和SELECT中的列创建覆盖索引也有助于提高查询性能。这样可以不用在查询时执行书签查找。
在前面提到的,增加太多索引将引起insert/update/delete时对这些索引列的修改。所以,找到平衡点才是最重要的。
分享到:




相关推荐
资源名称:SQL Server 2012王者归来——基础、安全、开发及性能优化内容简介:本书由浅入深,全面细致地讲述了SQL Server 2012的功能特性和开发应用。从SQL Server数据库基础到数据库安全,再到SQL Server开发及...
此文档中详细的记载了,SQL Server 索引中include的魅力(具有包含性列的索引),希望可以帮到下载的朋友们!
Sql Server——Sql性能优化Sql Server——Sql性能优化Sql Server——Sql性能优化Sql Server——Sql性能优化Sql Server——Sql性能优化Sql Server——Sql性能优化Sql Server——Sql性能优化Sql Server——Sql性能优化
sql server 2000完全实战——数据转换报务(dts)
SQL Server 索引结构及其使用(聚集索引和非聚集索引)的区别与实例讲解,提高查询速度。
该ppt详细描述sqlserver索引优化时带来的查询性能提升和更新锁开销,最后介绍表设计,字段数据类型的选择及使用适当的冗余减少表连接
SQL Server 2008存储结构——GAM和SGAM、PFS结构、IAM结构、DCM&BCM;
SQL Server 2008 R2概览——主数据服务和商务智能
SQLServer索引设计经验谈SQLServer索引设计经验谈
用于SqlServer的索引重建,全语句实现,可根据实际情况进行部分关键表的索引重建。
SQL Server 2005深入内幕——开发人员,最大的赢家:SQL Server 2005全新的开发特性.pdf
SqlServer索引工作原理
SQLServer课程设计报告——图书馆管理系统.doc
SQLserver查看索引列语句
Sqlserver索引分析,Sqlserver索引缺失,Sqlserver索引建议
SQL Server 索引结构及其使用
优化SQL Server索引的小技巧.doc
SQLserver索引失效举例.txt
在本文中,我将说明如何用SQLServer的工具来优化数据库索引的使用,本文还涉及到有关索引的一般性知识。关于索引的常识影响到数据库性能的最大因素就是索引。由于该问题的复杂性,我只可能简单的谈谈这个问题,不过...
2、 SQLServer2016-x64-CHS.iso(没有的可以去微软官网下载) 注意: 需要安装SQL全部功能则需要先安装JDK,若只需要安装数据库功能的话则可以不安装JDK。 鼠标双击打开事先下载好的SQLServer2016-x64-CHS.iso 鼠标...